Slashing load times by 10x with better scheduling

Pigment is a super fast growing company. Each day, new clients present unique challenges, adding to the platform's workload and pushing us to continually enhance its performance. This article explains how we successfully divided the loading time for certain clients by up to 10 times without touching to the execution time.
Understanding the load
At Pigment, we provide our clients with a solution to transform their raw data into polished reports, financial plans, and real-time visualizations. This empowers them to explore various scenarios, analyze results, and make informed decisions.
However, when dealing with the financial data of major companies like PVH, Figma, Mozilla, Kayak etc. the process of transitioning from data processing to comparing diverse scenarios across numerous perspectives can be extensive. Here's an illustration of a minuscule graph demonstrating the interdependencies among the tasks we need to execute, beginning from data importation:
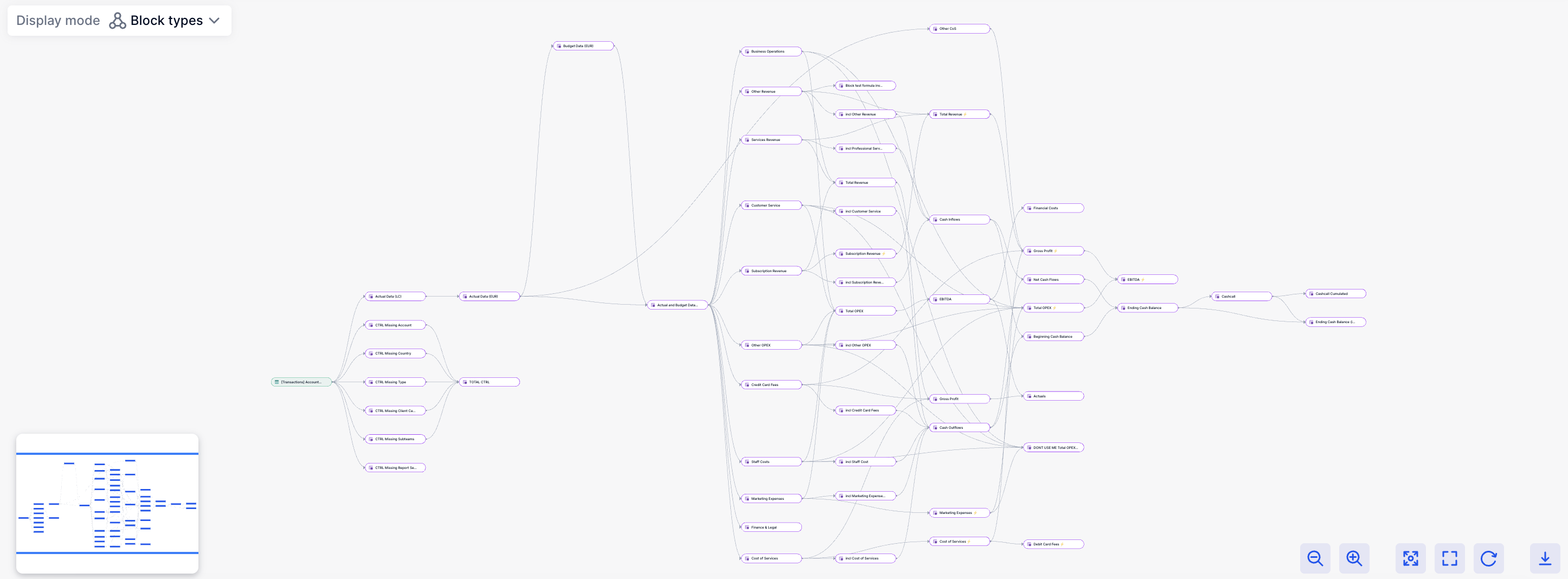
This implies that whenever a user modifies data within a node, we must calculate all subsequent dependencies downstream. What's more challenging is that we enable users to compare various "scenarios", allowing them to adjust nodes or the original data for comparison, potentially multiplying the number of nodes by the number of scenarios. A single change could result in thousands of executions 💥.
When dealing with dozens to hundreds of users for a single client all working at the same time, it's not feasible to manage everything simultaneously. Prioritizing tasks becomes crucial!
Finding the right prioritization rules
Prioritization algorithms typically fall under the umbrella of scheduling and depend on various external factors: Do we allow preemption? What is the cost of the job? What is the available quota? We won't delve into all of these topics here; they'd deserve their own article! Instead, our focus will be simple: Do the jobs we execute have significance?
Initially we assumed that a job matters if a user is observing its outcome. However, this is only partially accurate. A job doesn't exist in isolation; it's interconnected within a broader graph and has dependencies. Therefore, a job matters if it contributes to a result that a user is interested in. For instance, if we assume that our user is only concerned with "Debit card fees" in the graph, we can simplify the graph to:
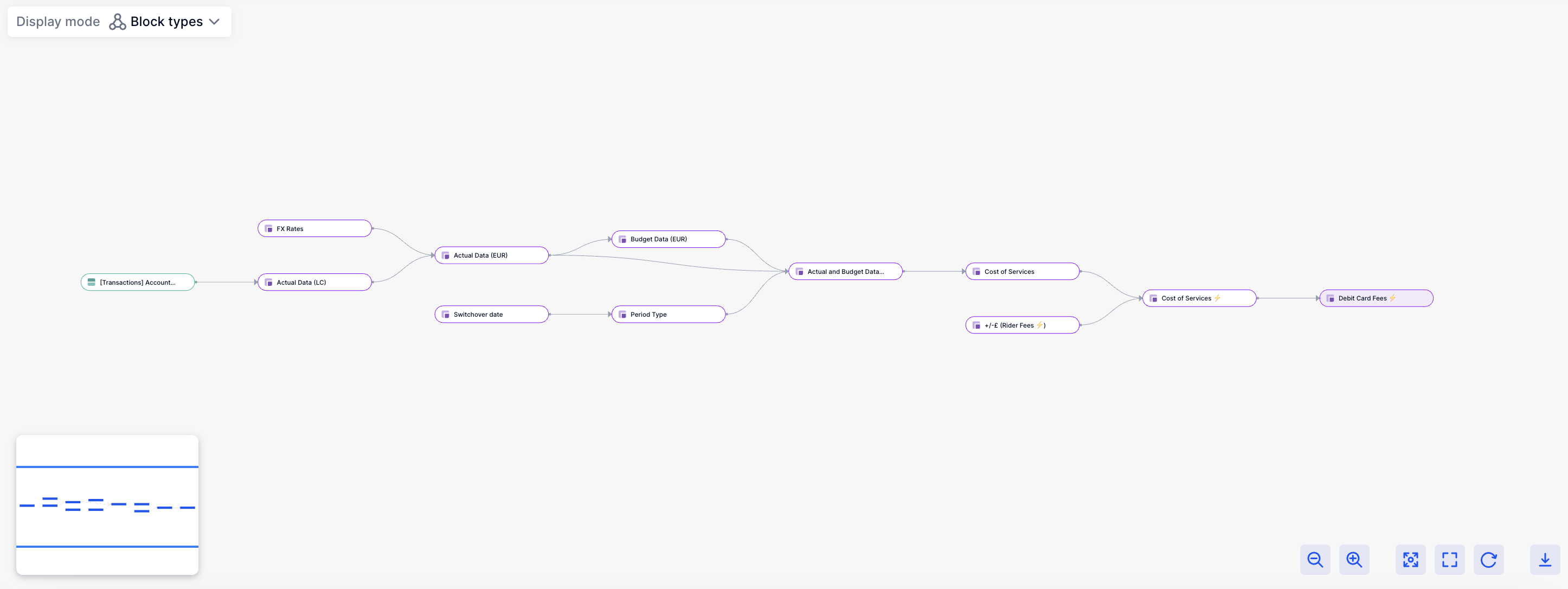
Considering this guideline, we conducted a simple test. We selected several clients with a high volume of executions, identified the jobs they were actively monitoring, and determined all the other jobs dependent on those. Then, we categorized the executions into two groups:
Useful jobs: Those that contributed to a job that someone monitored at least once during the day.Useless jobs: Those that did not.
Finally, we calculated a ratio: out of all the jobs awaiting execution, how many useless jobs were being run while there were useful jobs still pending scheduling? Surprisingly, it was found that between 40% to 80% of our executions could be postponed!
The implementation
Before we rolled out this feature, we had to seriously consider how it would handle scalability. We are dealing with potentially hundreds of subscription events pouring in every second, leading to thousands of interconnected jobs in dependency graphs with over 10,000 nodes. The global picture can be sumed up to:
- Identify the jobs impacting what users see.
- Find all the transitive dependencies leading to those jobs in the dependency graph
- Arrange those dependencies to guide our scheduler's decision-making.
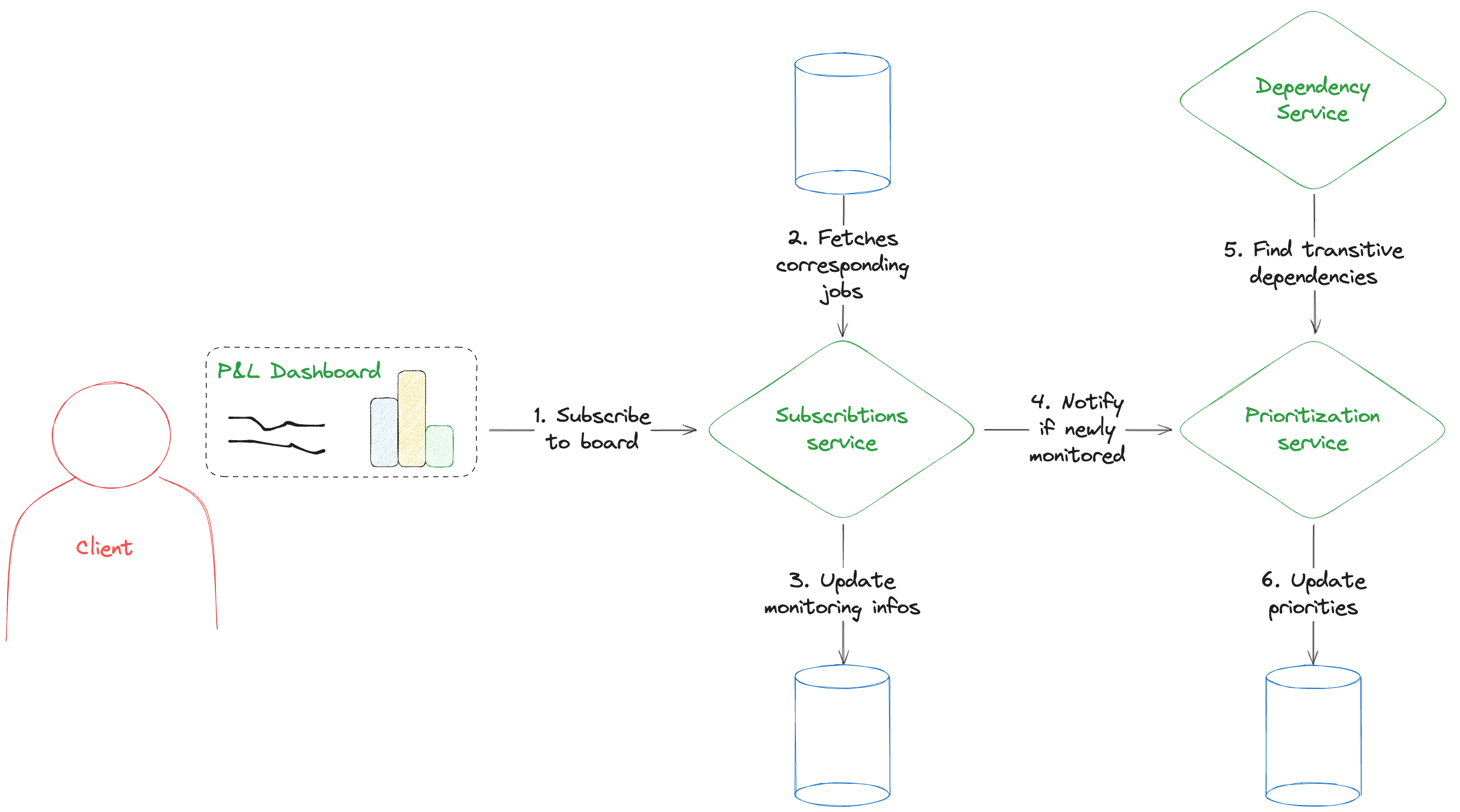
Moreover job priorities aren't set in stone. Users frequently switch between dashboards and dependencies in the graph get updated, which means we have to constantly reassess our priorities. We can't react to every change in real-time; we need a system that can handle the load, especially with Pigment's rapid growth each month.
So, we decided to focus on being responsive. After analyzing how users actually use the platform, we noticed they tend to focus on specific parts of their models for short bursts. Subscriptions often target the same set of jobs repeatedly. So, being overly reactive and only focusing on what's happening right now wouldn't be effective. Users move between dashboards, and we can't slow down computations for jobs they've temporarily left behind.
So what we did is implementating our prioritization based on a sliding window. Everytime we receive a subscription, we just update the time at which the targeted jobs were last monitored. If it newly enters the sliding window, it means that we may need to prioritize it and the prioritization service will get notified. If not, we won't bother trying.

The cleanup process will be handled by an asynchronous cron job. Periodically, it will gather all jobs within the sliding window and perform a complete recalculation of priorities. This allows us to automatically incorporate the latest version of the dependency graph and clean up both dependencies that are no longer accessible and dependencies of jobs that are no longer monitored.
This approach offers the advantage of being highly responsive to new jobs while significantly reducing the overall workload. However, it comes with the potential drawback of prioritizing jobs that are no longer actively monitored by our users. Nevertheless, if we find ourselves inundated with irrelevant jobs, we can always adjust by reducing the sliding window duration and increasing the frequency of the cron job.
Final results
Ultimately, this incredibly straightforward prioritization method enabled a reduction in the loading time of certain highly viewed segments for certain clients by up to 10! The numerous scenarios and applications that were not currently in use would no longer delay crucial executions, we consistently executed only the most efficient pathway to update what they were viewing.