How We Turbocharged Our Prediction Pipeline Using Dask

At Pigment, we provide a central platform for organizations to model and plan using their most valuable data. As part of that mission, enabling predictive insights is key. Our first implementation of predictions worked well for smaller datasets, but as more users began applying the feature to larger and more complex data models, we quickly hit the limits of a single-machine setup in terms of memory and compute.
To address this, we redesigned our infrastructure around a distributed Dask cluster, allowing us to scale horizontally and support much larger workloads. In this post, we’ll share the architecture of our new solution and key takeaways from adopting Dask in production.
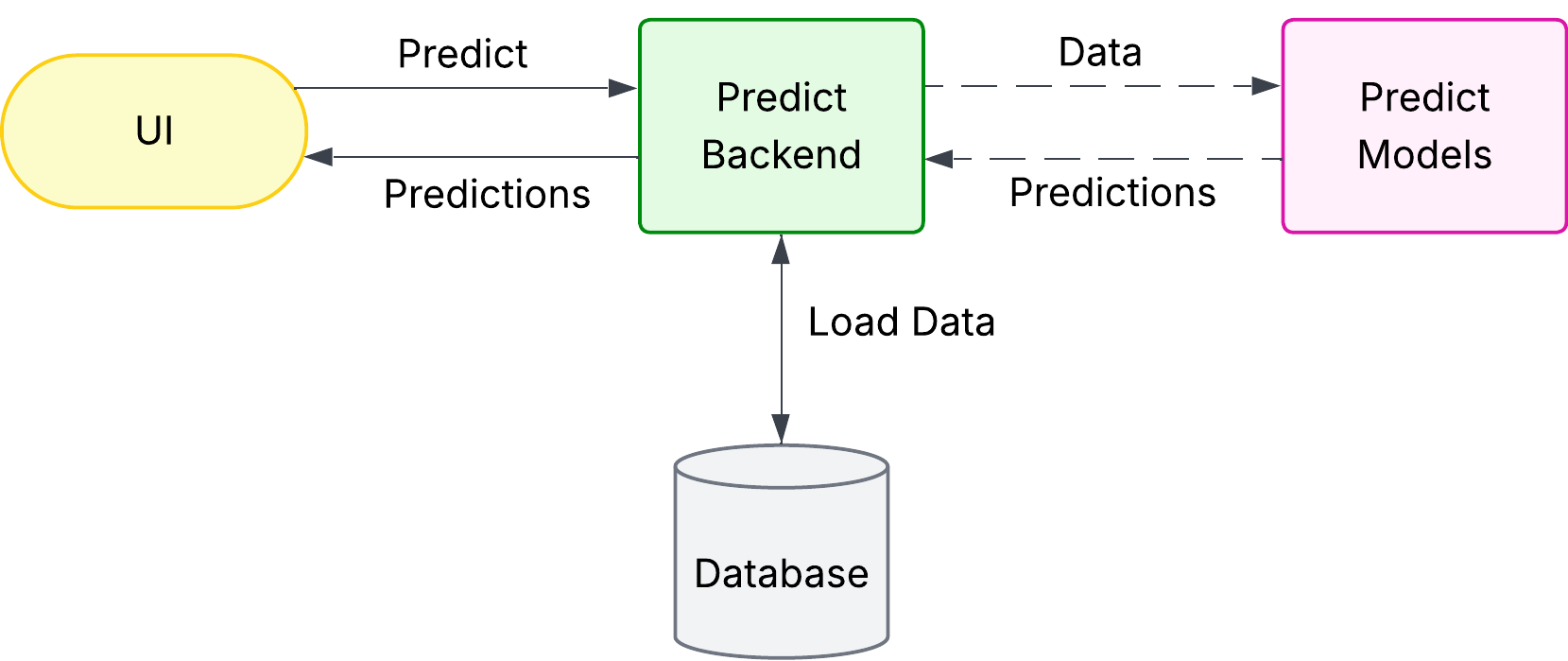
In our initial design, a prediction request was initiated from the UI and handled entirely by two backend pods (one C#, one Python). They would:
- Load all the necessary data from the database,
- Forward that data via gRPC to another pod running the forecasting model in Python,
- Wait for the forecast results, and then return them to the frontend.
While this setup was a good fit for a MVP, it quickly revealed several limitations as soon as users began applying forecasts to larger datasets. The key issues were:
- Fragile Long-Running Execution: Forecasting is a time-intensive process. If any gRPC or HTTP call failed—for example, due to a frontend reload or a pod restart—the entire prediction job would be interrupted and lost.
- Memory Bottlenecks: All data needed to be loaded into memory on a single backend pod. If the dataset was too large to fit, the pod would crash with an out-of-memory (OOM) error.
- CPU Constraints: The actual forecast computation, handled by the Python model pods, was CPU-bound. This limited throughput and made the system difficult to scale efficiently for larger or concurrent predictions.
Improved V2 Architecture
Queue-Based Communication
To improve reliability and resilience, we transitioned from gRPC-based communication to a queue-based architecture. This shift ensures that if no processing pod is available at a given moment, incoming requests are simply queued and processed as soon as resources become available. Additionally, if a pod is interrupted or shuts down mid-task, it can safely requeue its message, allowing another pod to resume processing without loss.
Since queues don’t support streaming in the same way gRPC does, we changed the data flow to use GCS (Google Cloud Storage) as an intermediate store. Specifically, data to be predicted is exported as Avro files to GCS and later consumed by Python-based prediction models. The model results are also written back to GCS in the same format.
The updated architecture is illustrated below:
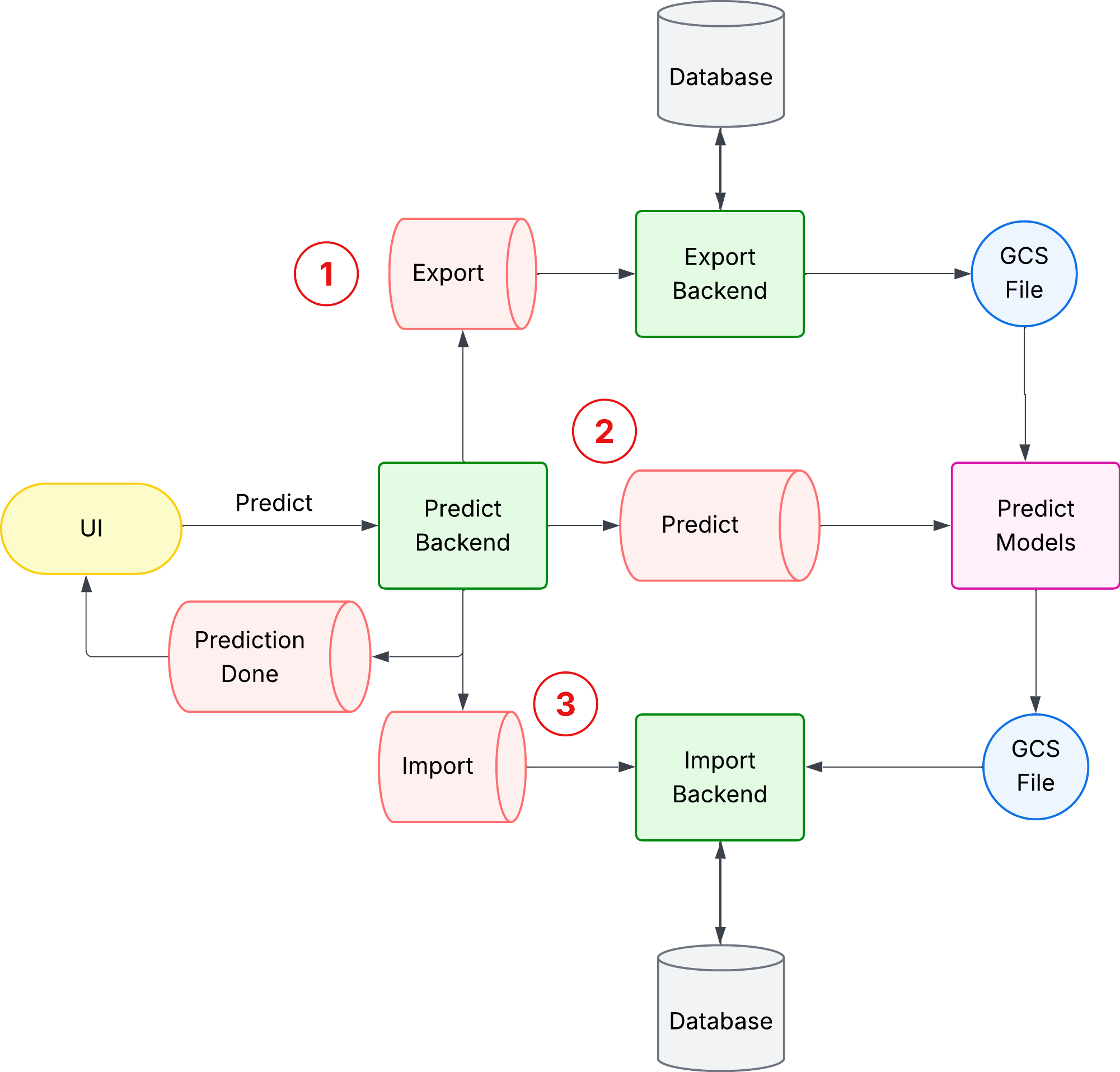
- Step 1: Export: The Predict Backend pushes an export request to the Export queue. This request is picked up by a dedicated system (Export Backend), which reads data from the database and writes it as an Avro file on GCS. Once the export is completed, a separate (not shown) notification queue signals the Predict Backend that the file is ready.
- Step 2: Predict: Upon receiving the export completion signal, the Predict Backend pushes a prediction request to the Predict queue. The Predict Models service picks this up, reads the GCS file, performs the prediction, and writes the output back to GCS as another Avro file. It then sends a notification (via another queue not shown) to inform the Predict Backend that predictions are ready.
- Step 3: Import: The Predict Backend now triggers the import phase by pushing a message to the Import queue. The Import Backend imports the predictions into the database as a new Metric. Finally, another queue notifies the Predict Backend once the import is completed. After this flow, the Predict Backend sends a “Prediction Done” event to the UI, enabling the user to view the forecasted values.
Implementing a Dask Cluster
At this stage, the Predict backend still ran as a single Python pod. This limited our ability to process large GCS files that couldn’t fit in memory and prevented us from distributing CPU load across multiple pods, which in turn made jobs slower.
To address this, we evaluated Apache Spark and Dask as parallel computing frameworks. We chose Dask because it integrates seamlessly with NumPy, preserves our existing Pythonic code and mental model, supports parallelism and out-of-core (bigger-than-memory) computation, and avoids the JVM/SQL-heavy shift required by Spark. Additionally, Spark comes with a steeper learning curve for our use case.
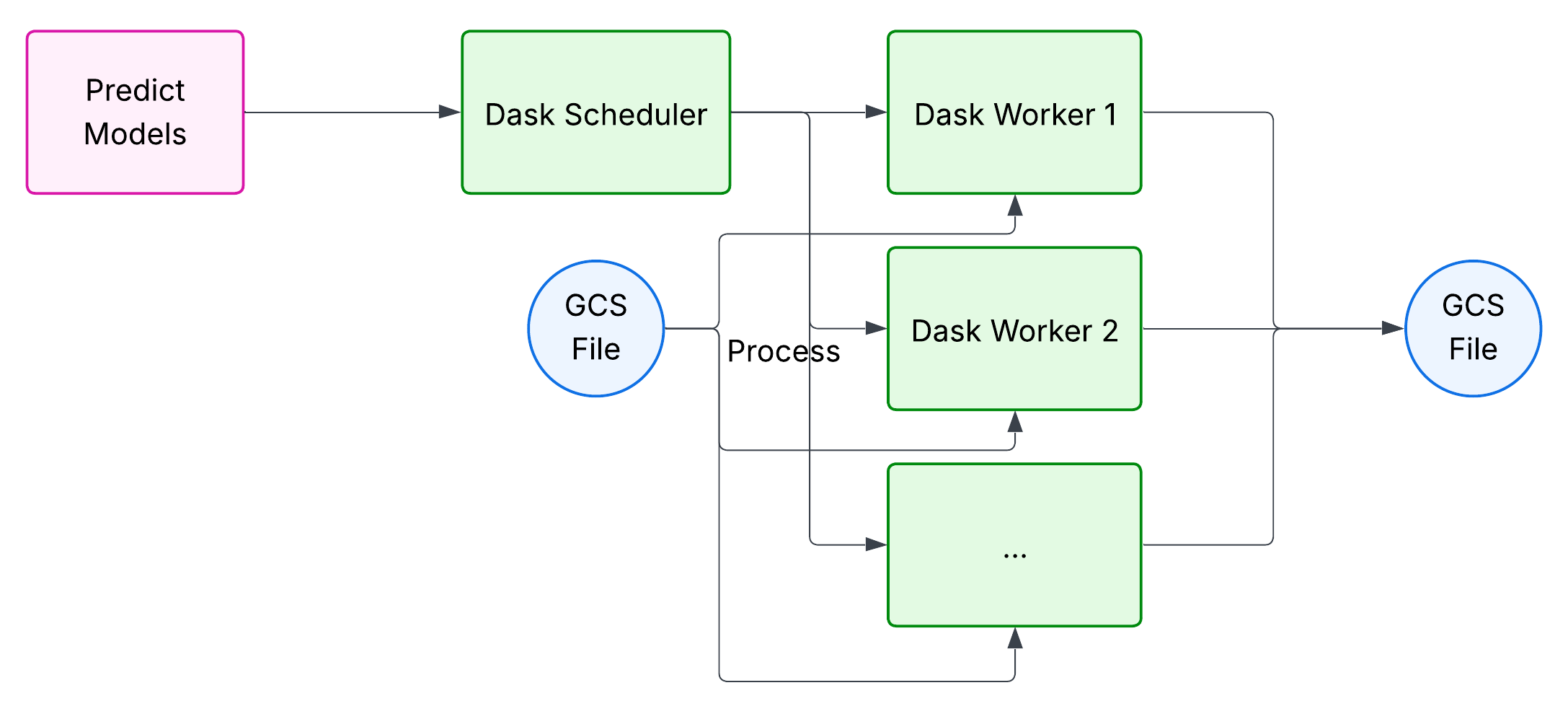
We refactored our workload to be Dask-compatible (a more complex task than initially expected) and introduced a Dask scheduler and Dask workers into our infrastructure. Instead of executing tasks directly, the Python pod now submits them to the scheduler, which distributes work across the workers.
Dask also provides Kubernetes-native operators, making it straightforward to integrate these components into our cluster. For example, the built-in DaskAutoScaler queries the scheduler about the workload and dynamically scales worker pods up or down to match demand.
Finally, the execution pattern was updated: each worker reads a partition of the input GCS file and writes back its corresponding partition of the output file. A key factor that enables this parallelization is the fact that our prediction models work on time series independently - each time series can be forecasted without knowledge of other series. This constrains us in terms of prediction models, but it also allows us to distribute the workload efficiently across workers, resulting in better resource utilization, and the ability to handle datasets much larger than a single pod's memory capacity.
Challenges
During implementation we faced several significant challenges.
Blue-Green Deployment
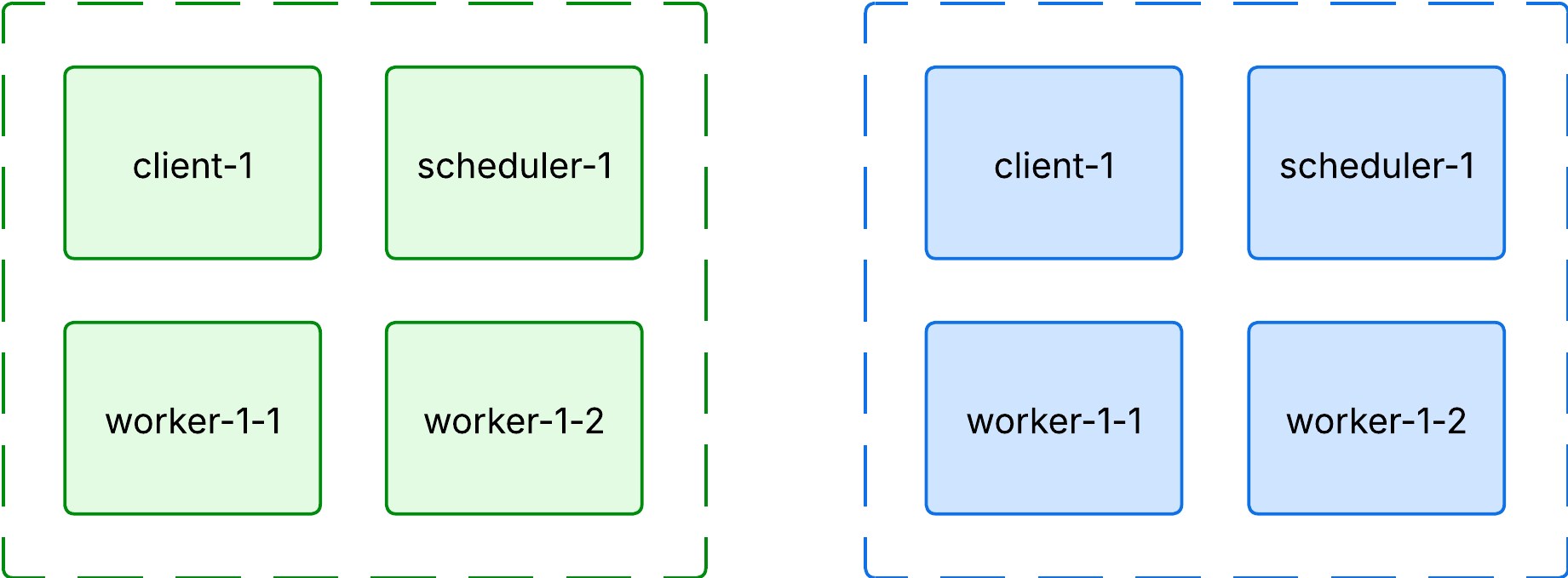
A critical requirement was ensuring that the Python library versions remained perfectly synchronized across the client, the Dask scheduler, and all Dask workers. Any mismatch would trigger warnings and could result in subtle, hard-to-debug errors.
To enforce this guarantee, we adapted our ArgoCD deployment pipeline to follow a blue-green deployment strategy. Using kustomizations and replacements, the commit SHA1 is appended to Kubernetes resources, ensuring that client-1 communicates only with scheduler-1. When deploying client-2, we can be confident that it only targets scheduler-2. This approach prevents cross-version communication between components during rollout.
Another difficulty emerged with the Dask Autoscaler. While it successfully scaled worker pods up in response to workload spikes, the additional pods would remain alive indefinitely, even after the cluster became idle. In extreme cases, a single job could spawn over 200 workers, creating a substantial cost burden if they were never released.
To address this, we dug into the autoscaler’s source code and ultimately submitted a pull request to the Dask repository. Although the fix hasn’t been merged yet, we currently run a custom version of the library that incorporates our patch.
Missing Features
Some required features were not available out-of-the-box, which forced us to build custom solutions:
-
Graceful Worker Shutdowns:
By default, workers could be terminated even if they were still processing tasks or had queued work. This sometimes caused tasks to be dropped permanently, leaving jobs stuck. To resolve this, we developed our own SchedulerPlugin that ensures active or queued tasks finish before a worker is killed.
-
Prediction Job Cancellation:
While Pigment’s UI allows cancellation of a prediction job, simply cancelling the associated Dask Future was insufficient — subtasks spawned by that job would continue running. To fix this, we implemented a custom mechanism:
- Each task is annotated with the Prediction Job ID.
- When a job is cancelled, all tasks carrying the same ID are terminated.
- This process is executed in a loop, since even dying tasks can spawn new subtasks that also need to be cleaned up.
The final result is a more robust and cost-efficient deployment pipeline, better autoscaling behavior, and safer job handling tailored to Pigment’s needs.
Conclusion
Adopting Dask was not without its challenges, but the benefits have been transformative. By moving from a single-pod execution model to a fully distributed cluster, we unlocked the ability to process massive datasets reliably, scale resources dynamically, and deliver faster predictions to our customers.
This shift has made our prediction pipeline far more resilient, cost-efficient, and capable of handling workloads that were previously out of reach. Most importantly, it enables Pigment to provide predictive insights at the scale our customers need, empowering them to make better, data-driven decisions with confidence.
Here is a glimpse of Dask’s mesmerizing UI when running a prediction job.